









Předpokládejme, že máte seznam, do kterého jsou s různou mírou „jednoduchosti“ zapsány počáteční údaje – například adresy nebo názvy společností:
 |  |
Je jasně vidět, že stejné město nebo společnost je zde přítomna v pestrých variantách, což samozřejmě v budoucnu způsobí mnoho problémů při práci s těmito tabulkami. A když se trochu zamyslíte, můžete najít spoustu příkladů podobných úkolů z jiných oblastí.
Nyní si představte, že k vám takto pokřivená data chodí pravidelně, tedy nejde o jednorázový příběh „ručně opravte, zapomeňte“, ale o problém pravidelně a ve velkém počtu buněk.
Co dělat? Nenahrazujte ručně křivý text 100500 XNUMXkrát správným pomocí pole „Najít a nahradit“ nebo kliknutím Ctrl+H?
První věc, která vás v takové situaci napadne, je provést hromadnou výměnu podle předem sestavené referenční knihy odpovídající nesprávným a správným možnostem – takto:

Bohužel, se zjevnou převahou takového úkolu, Microsoft Excel nemá jednoduché vestavěné metody pro jeho řešení. Začněme tím, že zjistíme, jak to udělat pomocí vzorců, aniž bychom zapojovali „těžké dělostřelectvo“ ve formě maker ve VBA nebo Power Query.
Případ 1. Hromadná úplná výměna
Začněme relativně jednoduchým případem – situací, kdy potřebujete nahradit starý křivý text novým. plně.
Řekněme, že máme dvě tabulky:

V první – původní pestré názvy firem. Ve druhé – referenční kniha korespondence. Najdeme-li v názvu firmy v první tabulce libovolné slovo ze sloupce Najít, pak je potřeba tento křivý název zcela nahradit správným – ze sloupce Náhradní druhá vyhledávací tabulka.
Pro pohodlí:
- Obě tabulky jsou převedeny na dynamické („inteligentní“) pomocí klávesové zkratky Ctrl+T nebo tým Vložit – Tabulka (Vložit — Tabulka).
- Na kartě, která se zobrazí Stavitel (Design) první jmenovaná tabulka Dataa druhá referenční tabulka – Střídání.
Abychom vysvětlili logiku vzorce, pojďme trochu zpovzdálí.
Vezmeme-li jako příklad první společnost z buňky A2 a dočasně zapomeneme na zbytek společností, zkusme určit, která možnost ze sloupce Najít se tam schází. Chcete-li to provést, vyberte libovolnou prázdnou buňku ve volné části listu a zadejte tam funkci NAJÍT (NALÉZT):

Tato funkce určuje, zda je daný podřetězec zahrnut (první argument jsou všechny hodnoty ze sloupce Najít) do zdrojového textu (první společnost z datové tabulky) a měl by vypsat buď pořadové číslo znaku, ze kterého byl text nalezen, nebo chybu, pokud nebyl nalezen podřetězec.
Trik je v tom, že protože jsme jako první argument zadali ne jednu, ale několik hodnot, tato funkce také vrátí ne jednu hodnotu, ale pole 3 prvků. Pokud nemáte nejnovější verzi Office 365, která podporuje dynamická pole, pak po zadání tohoto vzorce a kliknutí na vstoupit toto pole uvidíte přímo na listu:

Pokud máte předchozí verze Excelu, tak po kliknutí na vstoupit uvidíme pouze první hodnotu z výsledného pole, tedy chybu #HODNOTA! (#HODNOTA!).
Nemusíte se bát 🙂 Ve skutečnosti náš vzorec funguje a stále můžete vidět celou řadu výsledků, pokud vyberete zadanou funkci v řádku vzorců a stisknete klávesu F9(jen nezapomeňte stisknout Escvrátit se ke vzorci):

Výsledné pole výsledků znamená, že v původním křivém názvu společnosti (GK Morozko OAO) všech hodnot ve sloupci Najít našel teprve druhý (Morozko)a počínaje 4. znakem v řadě.
Nyní do našeho vzorce přidáme funkci NÁHLED(VZHLÉDNOUT):

Tato funkce má tři argumenty:
- Požadovaná hodnota – můžete použít jakékoli dostatečně velké číslo (hlavní je, že přesahuje délku jakéhokoli textu ve zdrojových datech)
- Zobrazený_vektor – rozsah nebo pole, kde hledáme požadovanou hodnotu. Zde je dříve představená funkce NAJÍT, která vrátí pole {#VALUE!:4:#VALUE!}
- Vektor_výsledky – rozsah, ze kterého chceme vrátit hodnotu, pokud je požadovaná hodnota nalezena v odpovídající buňce. Zde jsou správná jména ze sloupce Náhradní naši referenční tabulku.
Hlavním a nezřejmým rysem je zde funkce NÁHLED pokud neexistuje přesná shoda, vždy hledá nejbližší nejmenší (předchozí) hodnotu. Proto zadáním libovolného velkého čísla (například 9999) jako požadované hodnoty vynutíme NÁHLED najděte buňku s nejbližším nejmenším číslem (4) v poli {#VALUE!:4:#VALUE!} a vraťte odpovídající hodnotu z výsledného vektoru, tj. správný název firmy ze sloupce Náhradní.
Druhá nuance je, že technicky je náš vzorec maticový vzorec, protože funkce NAJÍT vrátí jako výsledek ne jednu, ale pole tří hodnot. Ale od funkce NÁHLED podporuje pole ihned po vybalení, pak tento vzorec nemusíme zadávat jako klasický maticový vzorec – pomocí klávesové zkratky Ctrl+směna+vstoupit. Postačí jednoduchý vstoupit.
To je vše. Doufám, že chápete logiku.
Zbývá přenést hotový vzorec do první buňky B2 sloupce Opravena – a náš úkol je vyřešen!

Samozřejmě, že s obyčejnými (ne chytrými) tabulkami tento vzorec funguje také skvěle (jen nezapomeňte na klíč F4 a oprava příslušných odkazů):

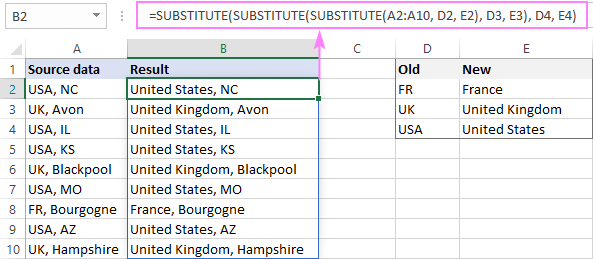
Případ 2. Částečná hromadná výměna
Tento případ je trochu složitější. Opět máme dvě „chytré“ tabulky:

První tabulka s křivě napsanými adresami, kterou je třeba opravit (nazval jsem ji Data 2). Druhá tabulka je referenční kniha, podle které je potřeba provést částečnou náhradu podřetězce uvnitř adresy (tuto tabulku jsem nazval Střídání2).
Zásadní rozdíl je v tom, že je potřeba nahradit pouze fragment původních dat – například první adresa má nesprávnou hodnotu "Svatý. Petrohrad” na pravé straně "Svatý. Petrohrad”, zbytek adresy (PSČ, ulice, dům) ponechte tak, jak je.
Hotový vzorec bude vypadat takto (pro snadnější vnímání jsem ho rozdělil na kolik řádků pomocí Další+vstoupit):

Hlavní práci zde vykonává standardní textová funkce Excelu NÁHRADNÍ (NÁHRADNÍ), který má 3 argumenty:
- Zdrojový text – první křivá adresa ze sloupce Adresa
- Co hledáme – zde použijeme trik s funkcí NÁHLED (VZHLÉDNOUT)z předchozího způsobu vytažení hodnoty ze sloupce Najít, který je zahrnut jako fragment v zakřivené adrese.
- Čím nahradit – stejným způsobem najdeme ze sloupce správnou hodnotu, která tomu odpovídá Náhradní.
Zadejte tento vzorec pomocí Ctrl+směna+vstoupit ani zde není potřeba, i když se ve skutečnosti jedná o maticový vzorec.
A je jasně vidět (viz chyby #N/A na předchozím obrázku), že takový vzorec má při vší své eleganci několik nevýhod:
- funkce SUBSTITUTE rozlišuje velká a malá písmena, takže „Spb“ na předposledním řádku nebylo v tabulce náhrad nalezeno. Chcete-li tento problém vyřešit, můžete použít funkci ZAMENIT (NAHRADIT), nebo předběžně přivést obě tabulky do stejného registru.
- Pokud je text zpočátku správný nebo v něm není žádný fragment, který by se dal nahradit (poslední řádek), pak náš vzorec vyvolá chybu. Tento moment lze neutralizovat zachycením a nahrazením chyb pomocí funkce IFERROR (IFERROR):

- Pokud původní text obsahuje několik fragmentů z adresáře najednou, pak náš vzorec nahradí pouze ten poslední (v 8. řádku, Ligovsky «Alej« Změnil na "pr-t", Ale "S-Pb" on "Svatý. Petrohrad” už ne, protože "S-Pb” je v adresáři výše). Tento problém lze vyřešit opětovným spuštěním našeho vlastního vzorce, ale již podél sloupce Opravena:


Není to místy dokonalé a těžkopádné, ale mnohem lepší než stejná manuální výměna, že? 🙂
PS
V příštím článku vymyslíme, jak takovou hromadnou substituci implementovat pomocí maker a Power Query.
- Jak funkce SUBSTITUTE funguje při nahrazení textu
- Nalezení přesného shodného textu pomocí funkce EXACT
- Vyhledávání a nahrazování rozlišují velká a malá písmena (VLOOKUP s rozlišováním malých a velkých písmen)