









Nedávno jsme diskutovali o použití funkce FILTER.XML k importu XML dat z internetu – hlavnímu úkolu, pro který je tato funkce ve skutečnosti určena. Po cestě se však objevilo další nečekané a krásné využití této funkce – pro rychlé rozdělení lepivého textu do buněk.
Řekněme, že máme datový sloupec, jako je tento:

Samozřejmě bych to pro pohodlí rád rozdělil do samostatných sloupců: název firmy, město, ulice, dům. Můžete to udělat mnoha různými způsoby:
- Použijte Text po sloupcích ze záložky Data (Data — Text do sloupců) a udělejte tři kroky Textový analyzátor. Pokud se ale údaje zítra změní, budete muset celý proces opakovat znovu.
- Načtěte tato data do Power Query a rozdělte je tam a poté je nahrajte zpět do listu a poté aktualizujte dotaz, když se data změní (což je již jednodušší).
- Pokud potřebujete aktualizovat za běhu, můžete napsat několik velmi složitých vzorců, abyste našli čárky a extrahovali text mezi nimi.
A můžete to udělat elegantněji a použít funkci FILTER.XML, ale co to má společného?
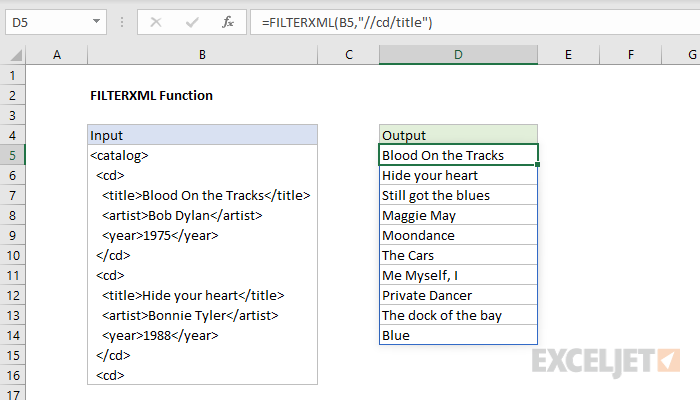
Funkce FILTER.XML přijímá jako svůj počáteční argument kód XML – text označený speciálními značkami a atributy, a poté jej analyzuje do svých komponent a extrahuje datové fragmenty, které potřebujeme. XML kód obvykle vypadá nějak takto:

V XML musí být každý datový prvek uzavřen ve značkách. Značka je nějaký text (ve výše uvedeném příkladu je to manažer, jméno, zisk) uzavřený v lomených závorkách. Tagy jsou vždy ve dvojicích – otevírací a zavírací (s lomítkem na začátek).
Funkce FILTER.XML dokáže jednoduše vytáhnout obsah všech tagů, které potřebujeme, například jména všech manažerů, a (hlavně) zobrazit všechny najednou v jednom seznamu. Naším úkolem je tedy přidat tagy do zdrojového textu a převést jej do XML kódu vhodného pro následnou analýzu pomocí funkce FILTER.XML.
Vezmeme-li jako příklad první adresu z našeho seznamu, budeme ji muset převést do této konstrukce:

Zavolal jsem globální značku otevření a zavření všech textů ta značky rámující každý prvek jsou s., ale můžete použít jakékoli jiné označení – na tom nezáleží.
Pokud z tohoto kódu odstraníme odsazení a zalomení řádků – mimochodem zcela nepovinné a přidané pouze pro přehlednost, vše se změní na řádek:
![]()
A už se dá poměrně snadno získat ze zdrojové adresy tak, že se v ní nahradí čárky pár tagy pomocí funkce NÁHRADNÍ (NÁHRADNÍ) a lepení se symbolem & na začátku a na konci úvodní a závěrečné značky:

Pro horizontální rozšíření výsledného rozsahu použijeme standardní funkci TRANSP (PŘEMÍSTIT), zabalit do něj náš vzorec:

Důležitou vlastností celého tohoto návrhu je, že v nové verzi Office 2021 a Office 365 s podporou dynamických polí nejsou pro zadávání potřeba žádná speciální gesta – stačí zadat a kliknout na vstoupit – vzorec sám zabírá počet buněk, které potřebuje, a vše funguje s třeskem. V předchozích verzích, kde ještě nebyla dynamická pole, bude potřeba před zadáním vzorce nejprve vybrat dostatečný počet prázdných buněk (můžete s okrajem) a po vytvoření vzorce stisknout klávesovou zkratku Ctrl+směna+vstoupitzadejte jej jako maticový vzorec.
Podobný trik lze použít při oddělování textu slepeného do jedné buňky zalomením řádku:

Jediný rozdíl oproti předchozímu příkladu je, že místo čárky zde nahradíme neviditelný znak zalomení řádku Alt + Enter, který lze ve vzorci zadat pomocí funkce CHAR kódem 10.
- Jemnosti práce se zalomením řádků (Alt + Enter) v Excelu
- Rozdělte text podle sloupců v Excelu
- Nahrazení textu textem SUBSTITUTE