









Obsah
Úkol přenosu dat z tabulky v souboru PDF do listu Microsoft Excel je vždy „zábavný“. Zvláště pokud nemáte drahý rozpoznávací software jako FineReader nebo něco podobného. Přímé kopírování většinou nevede k ničemu dobrému, protože. po vložení zkopírovaných dat na list se s největší pravděpodobností „slepí“ do jednoho sloupce. Takže je bude třeba pečlivě oddělit pomocí nástroje Text po sloupcích ze záložky Data (Data — Text do sloupců).
A kopírování je samozřejmě možné jen u těch PDF souborů, kde je textová vrstva, tedy u právě naskenovaného dokumentu z papíru do PDF to z principu fungovat nebude.
Ale není to tak smutné, opravdu 🙂
Pokud máte Office 2013 nebo 2016, pak za pár minut, bez dalších programů, je docela možné přenést data z PDF do aplikace Microsoft Excel. A Word a Power Query nám v tom pomohou.
Vezměme si například tuto PDF zprávu s hromadou textu, vzorců a tabulek z webu Evropské hospodářské komise:

… a zkuste to vytáhnout v Excelu, řekněte první tabulku:

Pojďme!
Krok 1. Otevřete PDF ve Wordu
Z nějakého důvodu to málokdo ví, ale od roku 2013 se Microsoft Word naučil otevírat a rozpoznávat soubory PDF (i naskenované, tedy bez textové vrstvy!). To se provádí zcela standardním způsobem: otevřete Word, klikněte Soubor – Otevřít (Soubor — Otevřít) a zadejte formát PDF v rozevíracím seznamu v pravém dolním rohu okna.
Poté vyberte požadovaný soubor PDF a klikněte Otevřená (Otevřeno). Word nám říká, že spustí OCR na tomto dokumentu na text:

Souhlasíme a za pár sekund uvidíme náš PDF otevřený pro úpravy již ve Wordu:

Z dokumentu samozřejmě částečně uletí design, styly, fonty, záhlaví a zápatí atd., ale to pro nás není důležité – potřebujeme pouze data z tabulek. V zásadě už v této fázi svádí tabulku z rozpoznaného dokumentu jednoduše zkopírovat do Wordu a jednoduše vložit do Excelu. Někdy to funguje, ale častěji to vede k nejrůznějším zkreslením dat – čísla se například mohou změnit v data nebo zůstat textem, jako v našem případě, protože. PDF používá neoddělovače:

Takže neškrtejme, ale udělejme vše trochu složitější, ale správně.
Krok 2: Uložte dokument jako webovou stránku
Pro následné načtení přijatých dat do Excelu (přes Power Query) je potřeba náš dokument ve Wordu uložit ve formátu webové stránky – tento formát je v tomto případě jakýmsi společným jmenovatelem Wordu a Excelu.
Chcete-li to provést, přejděte do nabídky Soubor – Uložit jako (Soubor — Uložit jako) nebo stiskněte klávesu F12 na klávesnici a v okně, které se otevře, vyberte typ souboru Webová stránka v jednom souboru (Webová stránka – jeden soubor):

Po uložení byste měli získat soubor s příponou mhtml (pokud vidíte přípony souborů v Průzkumníku).
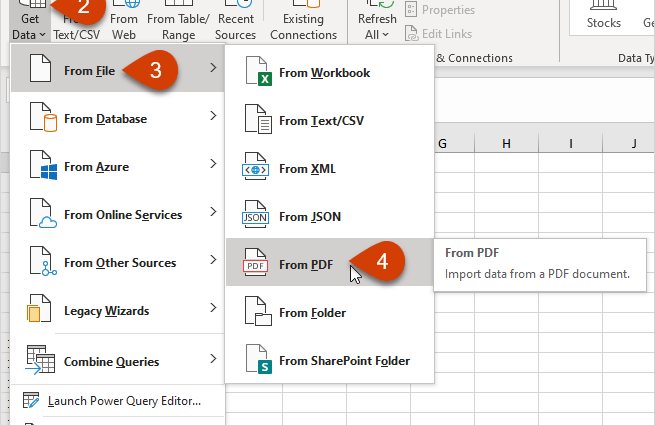
Fáze 3. Nahrání souboru do Excelu pomocí Power Query
Vytvořený MHTML soubor můžete otevřít přímo v Excelu, ale pak dostaneme za prvé veškerý obsah PDF najednou spolu s textem a hromadou zbytečných tabulek a zadruhé zase přijdeme o data kvůli nesprávným oddělovače. Import do Excelu tedy provedeme prostřednictvím doplňku Power Query. Jedná se o zcela bezplatný doplněk, pomocí kterého můžete nahrát data do Excelu z téměř jakéhokoli zdroje (soubory, složky, databáze, ERP systémy) a následně přijatá data všemožně transformovat a dát jim požadovaný tvar.
Pokud máte Excel 2010-2013, můžete si Power Query stáhnout z oficiálních stránek Microsoftu – po instalaci se vám zobrazí karta Dotaz na napájení. Pokud máte Excel 2016 nebo novější, pak nemusíte nic stahovat – veškerá funkčnost je již ve výchozím nastavení integrována do Excelu a nachází se na záložce Data (Datum) ve skupině Stahujte a převádějte (Získat a transformovat).
Jdeme tedy buď na záložku Data, nebo na kartě Dotaz na napájení a vybrat tým Chcete-li získat data or Vytvořit dotaz – ze souboru – z XML. Chcete-li zviditelnit nejen soubory XML, změňte filtry v rozevíracím seznamu v pravém dolním rohu okna na Všechny soubory (Všechny soubory) a zadejte náš soubor MHTML:

Upozorňujeme, že import nebude úspěšně dokončen, protože. Power Query od nás očekává XML, ale ve skutečnosti máme formát HTML. Proto v dalším okně, které se zobrazí, budete muset kliknout pravým tlačítkem myši na soubor nesrozumitelný pro Power Query a zadat jeho formát:

Poté bude soubor správně rozpoznán a uvidíme seznam všech tabulek, které obsahuje:

Obsah tabulek můžete zobrazit kliknutím levého tlačítka myši na bílé pozadí (nikoli ve slově Tabulka!) buněk ve sloupci Data.
Když je požadovaná tabulka definována, klikněte na zelené slovo Tabulka – a „propadnete se“ do jeho obsahu:

K „česání“ jeho obsahu zbývá udělat několik jednoduchých kroků, jmenovitě:
- odstranit nepotřebné sloupce (klikněte pravým tlačítkem na záhlaví sloupce – Odstranit)
- nahraďte tečky čárkami (vyberte sloupce, klikněte pravým tlačítkem – Výměna hodnot)
- odstranit rovnítko v záhlaví (vybrat sloupce, kliknout pravým tlačítkem – Výměna hodnot)
- odstranit horní řádek (Domů – Smazat řádky – Smazat horní řádky)
- odstranit prázdné řádky (Domů – Smazat řádky – Smazat prázdné řádky)
- zvedněte první řádek do záhlaví tabulky (Domů – Použijte první řádek jako nadpisy)
- odfiltrujte nepotřebná data pomocí filtru
Když je tabulka uvedena do normální podoby, lze ji pomocí příkazu vyložit na list zavřít a stáhnout (Zavřít a načíst) on Hlavní tab. A dostaneme takovou krásu, se kterou už můžeme pracovat:

- Transformace sloupce na tabulku pomocí Power Query
- Rozdělení lepivého textu do sloupců