









Obsah
V současné době má Microsoft Excel téměř pět set funkcí listu dostupných prostřednictvím okna Průvodce funkcí – tlačítko fx v řádku vzorců. Jedná se o velmi slušnou sestavu, ale přesto téměř každý uživatel dříve či později narazí na situaci, kdy tento seznam neobsahuje funkci, kterou potřebuje – jednoduše proto, že není v Excelu.
Doposud jediným způsobem, jak tento problém vyřešit, byla makra, tedy psaní vlastní uživatelsky definované funkce (UDF = User Defined Function) ve Visual Basicu, což vyžaduje patřičné programátorské znalosti a někdy to není vůbec snadné. S nejnovějšími aktualizacemi Office 365 se však situace změnila k lepšímu – do Excelu přibyla speciální funkce „wrapper“ LAMBDA. S jeho pomocí je nyní úkol tvorby vlastních funkcí vyřešen snadno a krásně.
Podívejme se na princip jeho použití v následujícím příkladu.
Jak pravděpodobně víte, Excel má několik funkcí analýzy data, které vám umožňují určit číslo dne, měsíce, týdne a roku pro dané datum. Ale z nějakého důvodu neexistuje funkce, která by určovala číslo čtvrtletí, což je také často potřeba, že? Pojďme tento nedostatek opravit a vytvořit s LAMBDA vlastní novou funkci k vyřešení tohoto problému.
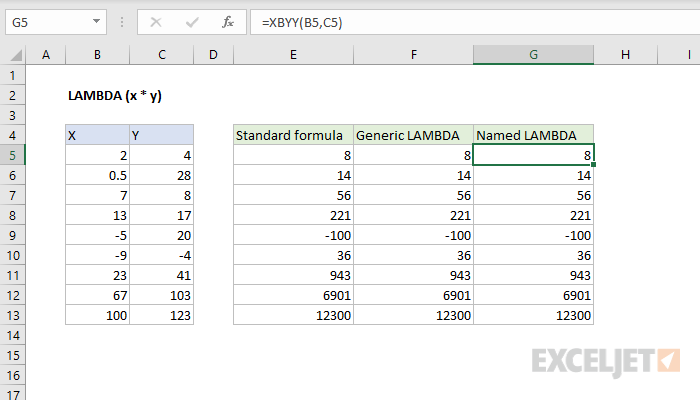
Krok 1. Napište vzorec
Začněme tím, že ručně obvyklým způsobem napíšeme do buňky listu vzorec, který vypočítá, co potřebujeme. V případě čísla čtvrtletí to lze provést například takto:

Krok 2. Zabalení do LAMBDA a testování
Nyní je čas použít novou funkci LAMBDA a zabalit do ní náš vzorec. Syntaxe funkce je následující:
=LAMBDA(Proměnná1; Proměnná2; … ProměnnáN ; Výraz)
kde názvy jedné nebo více proměnných jsou uvedeny jako první a poslední argument je vždy vzorec nebo vypočítaný výraz, který je používá. Názvy proměnných by neměly vypadat jako adresy buněk a neměly by obsahovat tečky.
V našem případě bude existovat pouze jedna proměnná – datum, pro které počítáme číslo čtvrtletí. Nazvěme pro to proměnnou, řekněme d. Poté zabalíme náš vzorec do funkce LAMBDA a nahrazením adresy původní buňky A2 fiktivním názvem proměnné dostaneme:

Upozorňujeme, že po takové transformaci náš vzorec (ve skutečnosti správně!) začal produkovat chybu, protože se do něj nyní nepřenáší původní datum z buňky A2. Pro testování a spolehlivost mu můžete předat argumenty tak, že je přidáte za funkci LAMBDA v závorce:

Krok 3. Vytvořte jméno
Nyní k té snadné a zábavné části. Otevíráme Správce jmen Karta vzorec (Vzorce — Správce jmen) a pomocí tlačítka vytvořte nový název Vytvořit (Vytvořit). Vymyslete a zadejte název naší budoucí funkce (např. Nomkvartala), a v terénu Odkaz (Odkaz) pečlivě zkopírujte z řádku vzorců a vložte naši funkci LAMBDA, pouze bez posledního argumentu (A2):

Všechno. Po kliknutí na OK vytvořenou funkci lze použít v libovolné buňce na libovolném listu tohoto sešitu:

Použití v jiných knihách
LAMBDA a dynamická pole
Vlastní funkce vytvořené pomocí funkce LAMBDA úspěšně podporovat práci s novými dynamickými poli a jejich funkcemi (FILTER, UNIK, GRADE) přidána do aplikace Microsoft Excel v roce 2020.
Řekněme, že chceme vytvořit novou uživatelsky definovanou funkci, která by porovnávala dva seznamy a vracela mezi nimi rozdíl – ty prvky z prvního seznamu, které nejsou ve druhém. Životní práce, ne? Dříve k tomu používali buď funkce a la VPR (VYHLEDAT)nebo kontingenční tabulky nebo dotazy Power Query. Nyní si vystačíte s jedním vzorcem:

V anglické verzi to bude:
=LAMBDA(a;b;ФИЛЬТР(a;СЧЁТЕСЛИ(b;a)=0))(A1:A6;C1:C10)
Zde je funkce COUNTIF počítá počet výskytů každého prvku prvního seznamu ve druhém a poté funkce FILTER vybere pouze ty z nich, kteří tyto výskyty neměli. Zabalením této struktury dovnitř LAMBDA a vytvoření pojmenovaného rozsahu na jeho základě s názvem, např. VYHLEDÁVÁNÍ DISTRIBUCE – získáme pohodlnou funkci, která vrátí výsledek porovnání dvou seznamů ve formě dynamického pole:

Pokud zdrojovými daty nejsou běžné, ale „chytré“ tabulky, naše funkce si také bez problémů poradí:

Dalším příkladem je dynamické dělení textu jeho převodem na XML a jeho následnou analýzou buňku po buňce pomocí funkce FILTER.XML, kterou jsme nedávno analyzovali. Abychom tuto složitou formuli nereprodukovali pokaždé ručně, bude jednodušší ji zabalit do LAMBDA a vytvořit na jejím základě dynamický rozsah, tedy novou kompaktní a pohodlnou funkci, pojmenovat ji například RAZDTEXT:

První argument této funkce bude buňka se zdrojovým textem a druhý – znak oddělovače a vrátí výsledek ve formě horizontálního dynamického pole. Kód funkce bude následující:
=LAMBDA(t;d; TRANSPOSE(FILTER.XML(“
Seznam příkladů je nekonečný – v každé situaci, kdy často musíte zadávat stejně dlouhý a těžkopádný vzorec, funkce LAMBDA znatelně usnadní život.
Rekurzivní výčet znaků
Všechny předchozí příklady ukázaly pouze jednu, nejzřetelnější stránku funkce LAMBDA – její použití jako „obalu“ pro zabalení dlouhých vzorců do ní a zjednodušení jejich zadávání. Ve skutečnosti má LAMBDA ještě jednu, mnohem hlubší stránku, která z ní dělá téměř plnohodnotný programovací jazyk.
Faktem je, že zásadně důležitou vlastností funkcí LAMBDA je schopnost je implementovat rekurze – logika výpočtů, kdy v procesu výpočtu funkce volá sama sebe. Ze zvyku to může znít strašidelně, ale v programování je rekurze běžná věc. I v makrech ve Visual Basic ji můžete implementovat a nyní, jak vidíte, přišla i do Excelu. Pokusme se tuto techniku pochopit na praktickém příkladu.
Předpokládejme, že chceme vytvořit uživatelsky definovanou funkci, která by odstranila všechny dané znaky ze zdrojového textu. Užitečnost takové funkce myslím nemusíte dokazovat – s její pomocí by bylo velmi pohodlné čistit podhozená vstupní data, že?
Oproti předchozím, nerekurzivním příkladům, nás však čekají dvě úskalí.
- Než začneme psát její kód, budeme muset vymyslet název pro naši funkci, protože v něm již bude tento název použit pro volání samotné funkce.
- Zadání takové rekurzivní funkce do buňky a její ladění uvedením argumentů v závorkách za LAMBDA (jak jsme to udělali dříve) nebude fungovat. Budete muset okamžitě vytvořit funkci „od nuly“. Správce jmen (správce jmen).
Nazvěme naši funkci, řekněme, CLEAN a chtěli bychom, aby měla dva argumenty – text, který se má vyčistit, a seznam vyloučených znaků jako textový řetězec:

Vytvořme, jako jsme to udělali dříve, na kartě vzorec в Správce jmen pojmenovaný rozsah, pojmenujte jej CLEAR a zadejte do pole Rozsah následující konstrukce:
=LAMBDA(t;d;IF(d=””;t;CLEAR(SUBSTITUTE(t;LEFT(d);””);MID(d;2;255))))
Zde proměnná t je původní text, který má být vymazán, a d je seznam znaků, které mají být vymazány.
Celé to funguje takto:
iterace 1
Fragment SUBSTITUTE(t;LEFT(d);””), jak asi tušíte, nahradí první znak z levého znaku ze sady d, který má být smazán ve zdrojovém textu t, prázdným textovým řetězcem, tj. odstraní „ A". Jako mezivýsledek dostaneme:
Vsh zkz n 125 rublů.
iterace 2
Poté se funkce zavolá a jako vstup (první argument) obdrží to, co zbylo po vyčištění v předchozím kroku, a druhým argumentem je řetězec vyloučených znaků začínající nikoli od prvního, ale od druhého znaku, tedy „BVGDEEGZIKLMNOPRSTUFHTSCHSHSHCHYYYYYA. ,” bez počátečního „A“ – to se provádí funkcí MID. Stejně jako dříve funkce vezme první znak zleva ze zbývajících (B) a nahradí jej v textu, který jí byl přidělen (Zkz n 125 rublů) prázdným řetězcem – dostaneme jako mezivýsledek:
125 ru.
iterace 3
Funkce se znovu zavolá a jako první argument obdrží to, co zbylo z textu, který má být vyčištěn v předchozí iteraci (Bsh zkz n 125 ru.), a jako druhý argument množinu vyloučených znaků zkrácenou o jeden další znak na vlevo, tj. „VGDEEGZIKLMNOPRSTUFHTSCHSHSHCHYYYYUYA.“ bez počátečního písmene „B“. Poté opět vezme první znak zleva (B) z této sady a odstraní jej z textu – dostaneme:
sh zkz n 125 ru.
A tak dále – doufám, že pochopíte. S každou iterací bude seznam znaků, které mají být odstraněny, vlevo oříznut a my vyhledáme a nahradíme další znak ze sady prázdným.
Když dojdou všechny znaky, budeme muset smyčku opustit – tuto roli právě vykonává funkce IF (LI), do které je zabalen náš design. Pokud nezbývají žádné znaky k vymazání (d=””), pak by se funkce již neměla volat, ale měla by jednoduše vrátit text, který má být vymazán (proměnná t) ve své konečné podobě.
Rekurzivní iterace buněk
Podobně můžete implementovat rekurzivní výčet buněk v daném rozsahu. Předpokládejme, že chceme vytvořit funkci lambda s názvem SEZNAM NÁHRAD pro velkoobchodní nahrazení fragmentů ve zdrojovém textu podle daného referenčního seznamu. Výsledek by měl vypadat takto:

Tito. na naší funkci SEZNAM NÁHRAD budou tři argumenty:
- buňka s textem ke zpracování (zdrojová adresa)
- první buňka sloupce s hodnotami, které se mají hledat z vyhledávání
- první buňku sloupce s náhradními hodnotami z vyhledávání
Funkce by měla jít v adresáři shora dolů a postupně nahradit všechny možnosti z levého sloupce Najít na odpovídající možnosti z pravého sloupce Náhradní. Můžete to implementovat pomocí následující rekurzivní funkce lambda:

Posun dolů při každé iteraci je realizován standardní funkcí Excelu LIKVIDACE (POSUN), který má v tomto případě tři argumenty – původní rozsah, posun řádku (1) a posun sloupce (0).
Jakmile se dostaneme na konec adresáře (n = „“), musíme rekurzi ukončit – přestaneme volat sami sebe a ve zdrojové textové proměnné t zobrazíme, co se nashromáždilo po všech náhradách.
To je vše. Žádná záludná makra ani dotazy Power Query – celý úkol řeší jedna funkce.
- Jak používat nové funkce dynamického pole aplikace Excel: FILTER, SORT, UNIC
- Nahrazení a vyčištění textu pomocí funkce SUBSTITUTE
- Vytváření maker a uživatelsky definovaných funkcí (UDF) ve VBA