









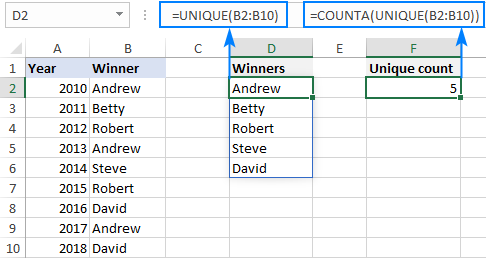
Formulace problému
Existuje datový rozsah, ve kterém se některé hodnoty opakují více než jednou:

Úkolem je spočítat počet jedinečných (neopakujících se) hodnot v rozsahu. Ve výše uvedeném příkladu je snadné vidět, že jsou ve skutečnosti zmíněny pouze čtyři možnosti.
Zvažme několik způsobů, jak to vyřešit.
Metoda 1. Pokud nejsou žádné prázdné buňky
Pokud jste si jisti, že v původním rozsahu dat nejsou žádné prázdné buňky, můžete použít krátký a elegantní maticový vzorec:

Nezapomeňte jej zadat jako maticový vzorec, tj. stiskněte po zadání vzorce nikoli Enter, ale kombinaci Ctrl + Shift + Enter.
Technicky vzato tento vzorec prochází všemi buňkami pole a pro každý prvek vypočítává počet jeho výskytů v rozsahu pomocí funkce COUNTIF (COUNTIF). Pokud to znázorníme jako další sloupec, bude to vypadat takto:

Poté se vypočtou zlomky 1/Počet výskytů pro každý prvek a všechny jsou sečteny, což nám dá počet jedinečných prvků:

Metoda 2. Pokud jsou prázdné buňky
Pokud jsou v rozsahu prázdné buňky, budete muset vzorec mírně vylepšit přidáním kontroly prázdných buněk (jinak dostaneme chybu dělení o 0 ve zlomku):

A je to.
- Jak extrahovat jedinečné prvky z rozsahu a odstranit duplikáty
- Jak barevně zvýraznit duplikáty v seznamu
- Jak porovnat dva rozsahy pro duplikáty
- Extrahujte jedinečné záznamy z tabulky podle daného sloupce pomocí doplňku PLEX